Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, the World’s Largest and Most Powerful Generative Language Model | NVIDIA Technical Blog
🚀 Unleash the power of MT-NLG – the world's largest and most robust language model with a whopping 530 billion parameters! 🤯 Excel in various NLP tasks like completion prediction and reading comprehension with cutting-edge innovations from Microsoft and NVIDIA. #NLG #MTNLG530B #AI 🤖🔥
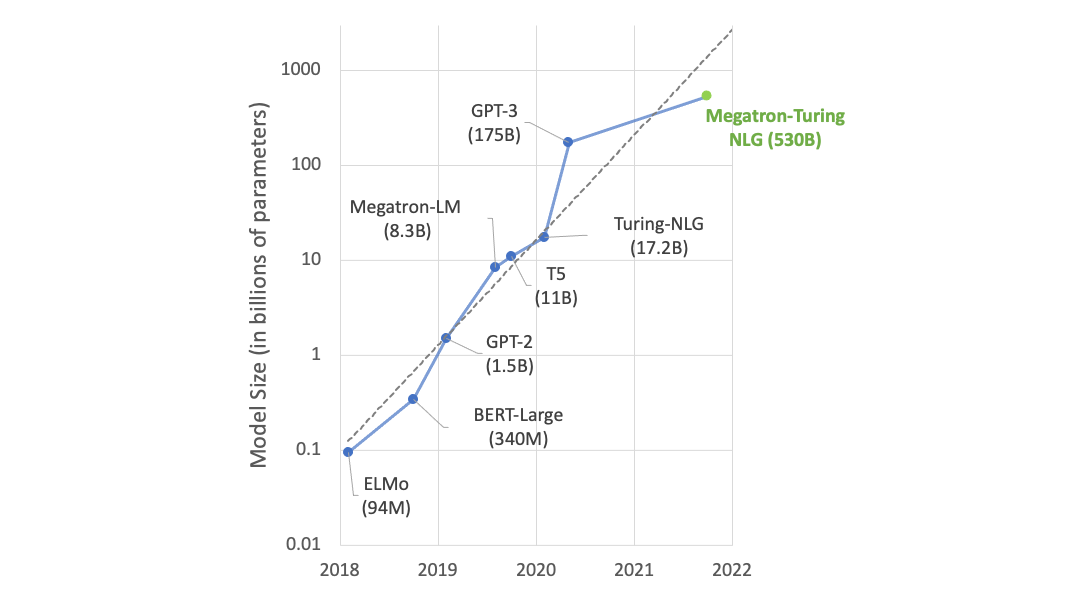
- The MT-NLG model, developed by Microsoft and NVIDIA, is the largest and most powerful transformer-based language model with 530 billion parameters.
- It excels in various natural language tasks such as completion prediction, reading comprehension, commonsense reasoning, and word sense disambiguation.
- Training large-scale language models like MT-NLG requires innovative strategies due to memory limitations and long training times.
- The training infrastructure leverages NVIDIA A100 GPUs and HDR InfiniBand networking for efficient parallelism.
- A 3D parallel system combining data, pipeline, and tensor-slicing parallelism was developed by NVIDIA Megatron-LM and Microsoft DeepSpeed for training.
- MT-NLG achieved state-of-the-art results in zero-shot, one-shot, and few-shot settings across multiple NLP tasks.
- The model demonstrated improvements in tasks involving comparison or relation-finding, showcasing faster learning capabilities of larger models.
- Despite its advancements, MT-NLG, like other large language models, can exhibit biases picked up from training data.
- Microsoft and NVIDIA are actively researching methods to quantify and mitigate biases in language models like MT-NLG.
- The collaboration between supercomputers like NVIDIA Selene and Azure NDv4, along with software breakthroughs, has propelled the development of models like MT-NLG.